
1·
5 days agoAI LLMs simply are better at surfacing it
Ok, but how exactly? Is there some magical emergent property of LLMs that guides them to filter out the garbage from the quality content?
old profile: /u/antonim@lemmy.world
AI LLMs simply are better at surfacing it
Ok, but how exactly? Is there some magical emergent property of LLMs that guides them to filter out the garbage from the quality content?
If you don’t feel like discussing this and won’t do anything more than deliberately miss the point, you don’t have to reply to me at all.
they’re a great use in surfacing information that is discussed and available, but might be buried with no SEO behind it to surface it
This is what I’ve seen many people claim. But it is a weak compliment for AI, and more of a criticism of the current web search engines. Why is that information unavailable to search engines, but is available to LLMs? If someone has put in the work to find and feed the quality content to LLMs, why couldn’t that same effort have been invested in Google Search?
deleted by creator
Here in my southeast European shithole I’m not worrying about my tax money, the upgrade is going to be pretty cheap, they’re just going to switch from unlicensed XP to unlicensed Win7.
Yep, but I didn’t mention that because it’s not a part of the “Wayback Machine”, it’s just the general “Internet Archive” business of archiving media, which is for now still completely unavailable. (I’ve uploaded dozens of public-domain books there myself, and I’m really missing it…)
You can (well, could) put in any live URL there and IA would take a snapshot of the current page on your request. They also actively crawl the web and take new snapshots on their own. All of that counts as ‘writing’ to the database.
it is quite literally named the “land of the blacks” after all that is what Egypt means
Egypt is from Greek and definitely doesn’t mean that. The Egyptian endonym was kmt (traditionally pronounced as kemet), which is interpreted as “black land” (km means “black”, -t is a nominal suffix, so it might be translated as black-ness, not at all “quite literally land of the blacks”), most likely referring to the fertile black soil around the Nile river. Trying to interpret that as “land of the blacks” should be suspicious already due to the fact people would hardly name themselves after their most ordinary physical characteristic; the Egyptians might call themselves black only if they were surrounded by non-black people and could view that as their own special characteristic, but they certainly neighboured and had contact with black peoples. And either way one has to wonder if the ancient views of white and black skin were meaningfully comparable to modern western ones. On the other hand, the fertile black soil most certainly is a differentia specifica of the settled Egyptian land that is surrounded by a desert.
More screenshots are here: https://xcancel.com/p9cker_girl/status/1844203626681794716
What I find odd is that the message that they actually left on the site has nothing to do with Palestine, just childish “lol btfo” sort of message. So I wouldn’t be surprised if these guys aren’t the ones who actually did it, and it’s merely a false flag to make pro-Palestinian protesters look like idiotic assholes.
I don’t get the impression you’ve ever made any substantial contributions to Wikipedia, and thus have misguided ideas about what would be actually helpful to the editors and conductive to producing better articles. Your proposal about translations is especially telling, because the machine-assisted translations (i.e. with built-in tools) have already existed on WP long before the recent explosion of LLMs.
In short, your proposals either: 1. already exist, 2. would still risk distorsion, oversimplification, made-up bullshit and feedback loops, 3. are likely very complex and expensive to build, or 4. are straight up impossible.
Good WP articles are written by people who have actually read some scholarly articles on the subject, including those that aren’t easily available online (so LLMs are massively stunted by default). Having an LLM re-write a “poorly worded” article would at best be like polishing a turd (poorly worded articles are usually written by people who don’t know much about the subject in the first place, so there’s not much material for the LLM to actually improve), and more likely it would introduce a ton of biases on its own (as well as the usual asinine writing style).
Thankfully, as far as I’ve seen the WP community is generally skeptical of AI tools, so I don’t expect such nonsense to have much of an influence on the site.
As far as Wikipedia is concerned, there is pretty much no way to use LLMs correctly, because probably each major model includes Wikipedia in its training dataset, and using WP to improve WP is… not a good idea. It probably doesn’t require an essay to explain why it’s bad to create and mechanise a loop of bias in an encyclopedia.
It has custom user-made themes that are dark mode, so it probably has dozens of dark modes.

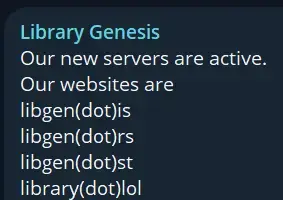
Hell, a lot of the time I just go directly to Sci-Hub / Anna’s Archive because it’s literally faster than searching for my university and logging in.
This hasn’t been reported on much, but I actually checked what that “competition” really was, back when the image won the prize. It was some local festival in Bumfucknowhere, USA, which among various other events (sport events, food tasting, that sort of stuff) included an art competition. I doubt the jury was made up of highly experienced art critics.
And besides, people should trust their own eyes. If you like the picture, you like it, and if you don’t, you don’t. Appealing to the critics as a source of objective artistic judgment is naive, and I say that as someone who has published some art criticism myself.
I mean all of that is true, but, speaking as someone from Croatia - we don’t follow safety standards and regulations here anyway even with native workers, the quality of the bridge would definitely not be any better had Croats built it, and I doubt there even is the adequate workforce and know-how within Croatia that would be needed for such a massive and complex job. I would unironically expect the deadlines to be breached by several years had the job been given to a local company. We also aren’t a rich country by European standards, so the price was probably a crucial factor.
In case you’re worrying about general Chinese influence on Croatian politics, that’s not really a problem, our govt is strongly pro-EU (for better and for worse), as well as much of the population.
What the hell is “sus” about that?
Hmm, “1200-600 CE”?
https://samblog.seattleartmuseum.org/2018/08/whale-effigy-charm/
Looks like it should be 1200-1600 CE (or AD).

That might depend on where you live, but generally no, I think.





{kind=link}
{kind=link}
And that’s more or less what I was aiming for, so we’re back at square one. What you wrote is in line with my first comment:
The point is that there isn’t something that makes AI inherently superior to ordinary search engines. (Personally I haven’t found AI to be superior at all, but that’s a different topic.) The difference in quality is mainly a consequence of some corporate fuckery to wring out more money from the investors and/or advertisers and/or users at the given moment. AI is good (according to you) just because search engines suck.