
- cross-posted to:
- technology@lemmy.world
- cross-posted to:
- technology@lemmy.world
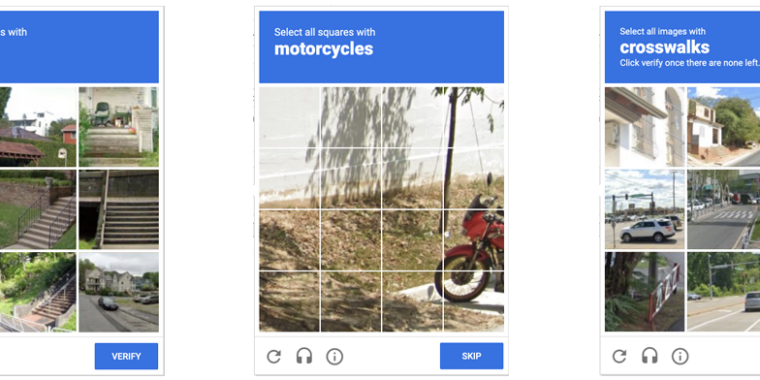
Anyone who has been surfing the web for a while is probably used to clicking through a CAPTCHA grid of street images, identifying everyday objects to prove that they’re a human and not an automated bot. Now, though, new research claims that locally run bots using specially trained image-recognition models can match human-level performance in this style of CAPTCHA, achieving a 100 percent success rate despite being decidedly not human.
ETH Zurich PhD student Andreas Plesner and his colleagues’ new research, available as a pre-print paper, focuses on Google’s ReCAPTCHA v2, which challenges users to identify which street images in a grid contain items like bicycles, crosswalks, mountains, stairs, or traffic lights. Google began phasing that system out years ago in favor of an “invisible” reCAPTCHA v3 that analyzes user interactions rather than offering an explicit challenge.
Despite this, the older reCAPTCHA v2 is still used by millions of websites. And even sites that use the updated reCAPTCHA v3 will sometimes use reCAPTCHA v2 as a fallback when the updated system gives a user a low “human” confidence rating.
You must log in or register to comment.
I fucking hate these. I’ve seen old people that don’t know any better get stuck on these for at least 30 minutes.
it’s super ableist. if someone has poor vision or colorblindness chances are they’re going to miss things.
I have regular everything and I still fuck them up. “click the ones with a fire hydrant”. But a tiny piece of fire hydrant is spilling into another box. Does it count? Does it not count? Good luck!!
I had one the other day that was deep fried jpegs to the max. Like, what the fuck am I supposed to do.
Sprinkle powdered sugar on them. Delicious deep fried jpegs.
Spillovers into other boxes definitely count…
I don’t want to do this next part but I can’t resist…
Just ask my girlfriend…
Ba dum tiss
FYI as someone that’s colorblind these captcha’s don’t seem to have anything specially relevant to being colorblind in them.
Now if they start showing me a dozen traffic cones and asking me to pick the green one, we might have a problem.
They offer a sound option right below.
a hard to see option, aptly enough
deleted by creator
And yet I can’t beat the CAPTCHAs because reCAPTCHA doesn’t like VPNs lol
Captcha these days isn’t even really a CAPTCHA in the traditional sense since most of the work it does is based on filtering of IP and browser fingerprinting, with a certain level of gamification because the goal is not just to keep out the people they fight against, but to waste their time, would work great if it didn’t waste normal people’s time, while real bad actors have easy ways to get around it.
deleted by creator
Fellow vpn user here, it’s been really bad lately. I’m definitely installing this.
I was going to say I’ve straight up just left whatever website I was trying to access because I was stuck in some endless loop of clicking on street crossings, buses, bikes, and street lights.
CAPTCHA doesn’t stop bots, and let us be honest, it never really did. It frustrated the hell out of people though, and caused people to waste time doing these challenges. Meanwhile even before AI bad actors and bots could get past it simply by using captcha solver services run by exploited humans solving captchas for the service.
It’s a display of security theater meant to make normies feel safe but in reality doesn’t stop most bad actors.
Meanwhile I sometimes fail those. I have been locked out of applications because I missed a square of a bus, or perhaps because I like to be efficient in my mouse cursor movements. I ducking hate CAPTCHAs.
This is actually a good sign for self driving. Google was using this data as a training set for Waymo. If AI is accurately identifying vehicles and traffic markings, it should be able to process interactions with them easier.
As I understand it, the point of those captchas was never really “bots can’t identify these things” (though you’re right on that it was used to train). They use cursor movement, clicks, and other behaviours while you’re solving it to detect if you are a bot or not.
The image choosing was always just to train their own bots
It’s a combination.
Most captchas goals generally aren’t 100% prevention, it’s to put a workload in front, this makes spamming the site cost money, a bankrolled attempt could just as easily outsource the captchas to real humans.
a bankrolled attempt could just as easily outsource the captchas to real humans.
Exactly. I’ve been using 2captcha for that for over a decade now
Is that why I’m asked to do this over and over for 14 million times when I’m on a VPN?
It is probably part of it, yeah. But to be clear I’m not a captcha expert or anything, just a layman.
Since I started getting good at yosu and that fishing mini game in farmrpg I’ve been failing more captchas. I wonder if they’re related knowing this
The annoying thing is that they held us hostage for our free labor, but the results are proprietary for Google’s benefit only.
That training data ought to be forced to be made freely available to the public, since we’re the ones who actually created it.
Afaik this is precisely what the captcha data was intended for - training AI models. Originally leveraged machine learning. LLMs are a slightly different paradigm but same purpose and results here.
i hope you’re joking. please, tell me you’re joking?
Its never been confirmed by Google, so I may be wrong. It still tracks that the data harvesting company with a AI self driving car project would use free human labor to identify road hazards.
I was referring to the “This is actually a good sign for self driving” part of their comment.
The captcha circumvention arms race has been going on for over two decades, and every new type of captcha has and will continue to be broken as soon as it’s widely deployed enough that someone is motivated to spend the time to.
So, the notion that an academic paper about breaking the current generation of traffic-related captchas (something which the captcha solving industry has been doing for years with a pretty high success rate already) is “good news” for the autonomous vehicle industry (who has also been able to identify such objects well enough to continue existing and getting more regulatory approval for years now) is…

Not really. I’m not even sure what you’re disagreeing with based on the above comment.
My point is that if bog standard AI can accurately identify all of the road information from pictures, that is good news for self driving.
What was once a nearly impossible task for computers is now mundane, and can be used to improve safety/utility for self driving, especially for FOSS projects like comma.ai
Removed by mod
Aren’t these Captchas designed to get training data for AI models anyway?
“System does what it was designed to do” doesn’t feel that surprising…
Aren’t these Captchas designed to get training data for AI models anyway?
Yes and no, the captchas are just meant to be hard for computers to solve but easier for humans. People saw that, and thought that “if we’re making people do this might as well have them do something useful” not meant to be malevolent- and the purpose is still stopping bots, training them is a side-effect.
No, you’re wrong, the Traffic Light examples ARE specifically to gather data to train models. Being a good Captcha was just a byproduct of that. If people just wanted a good captcha they wouldn’t need hundreds of millions of photos of street lights and bicycles.
No, you’re wrong, the Traffic Light examples ARE specifically to gather data to train models.
No you’re wrong, because the sites that embed those captchas on their page are not doing that to help good.
If people just wanted a good captcha they wouldn’t need hundreds of millions of photos of street lights and bicycles.
Yes, they are getting something productive out of the human labor that would be done anyways. Trust me as a web developer, and web scraper, some kind of captcha is necessary for many free services to be useful/economically viable. The core of a good captcha is just making it marginally more expensive for the scraper/bot than it is for you.
The sites don’t create the captcha, you yourself just said it was embedded there.
They embed for a reason… And the captchas wouldn’t exist if they weren’t embedded anywhere
Finitebanjo is right. Yes they are used to fight spam and bots but they way they do it us is picked intentionally to train ai.
https://medium.com/@yennhi95zz/how-google-trains-ai-with-your-help-through-captcha-876cb4eb4d01
Also from the Wikipedia article “Google profits from reCAPTCHA users as free workers to improve its AI research.” https://en.m.wikipedia.org/wiki/ReCAPTCHA
they do it us is picked intentionally to train ai.
Yes like I said, the challenges were picked to be useful. But some form of challenge would’ve been chosen regardless.
the new ones suck so fucking much though
If I see the newer ones pop up at all I just skip what ever the task is that was requiring me to bother with it.
i love when websites (twitter is a really bad example) hit me with like 8 captchas, and then if i get my username/password wrong i have to do another 8. It’s just so obviously gaming for training data on shit lmao.
What is it actually training? Google owns captcha right?
i have no clue, but i would assume it’s native to twitter if they’re pushing it that hard, either that or someone is paying a lot of money for that captcha access lol.
So can we stop using those damn things? They’re super annoying!
I’m kind of hoping the AI permanently beats them. I hate them too.
Just means they’ll get harder, but maybe not for people, just needs to be harder for a computer
Technically the “correct” answer is set by the highest percentage of people choosing it. EG: 19 people select Box A and 1 selects Box B, then the machine decides Box A is in fact correct.
That means these AI could be selecting the wrong answers for all anybody knows, if enough of them are answering the prompts, and still passing.
I fail more of those checks then these AI bots do. Surreal.
It seems like every other captcha I get has a picture of a moped and asks to click for a motorcycle. When I don’t click on the moped it says I’m wrong. Pisses me off.
than* these AI bots
Greetings fellow human!
01001000 01101111 01110111 00100000 01100100 01101111 00100000 01111001 01101111 01110101 00100000 01100100 01101111 00111111
Just be very general, don’t get stuck in the details.
It goes against my human nature to not overanalyze.
leaves plastic banana under your bed
You’ll find that, months from now, and you won’t know where it came from, or why it’s there.
Bots are answering them wrong. Google takes the most submitted answer as truth.
I just close the page usually if I see one of these ones, I don’t have the patience to click all the boxes and then it just sends you a different one.
Unfortunately they’re on pages that I absolutely need to get into because my money is stored behind them. I cannot stand them, and I generally agree with you, if some random site has me doing a captcha in leaving.
So…if CAPTCHA are already beaten by bots what’s the point if it still exists ? to mock our weakness ?
In the old days CAPTCHA could do its job, but nowadays nah…even crawler/scrapper/meta bots can bypass it easily.
The real question is why do we as real humans still often fail to beat CHAPTCHA? Are we less human? Are we really robots in CHAPTCHA perspective ?To train Google/Cloudflare’s AI tools, and to double check against DDOS. That’s it.
So now we’re going to have AI training other AIs
Wait, there’s a movie about this …
Just because it’s possible, doesn’t mean it’s common.
Buster is awesome to get past recaptcha. I use it with my own Speech to Text API key since its free from Google. Using Google to beat Google.
If you’re using a personal api from google, is that a way that google can track you? Part of using a VPN, noscript and adblock for me is to prevent that kind of tracking.
Nothing is truly free with Google. So ya, most likely they are tracking. If you dont want to use Google, there are other options on their wiki
https://github.com/dessant/buster/wiki
If not, you can use a dummy account just for this.
It’s so funny that this exists. I’m going to check it out!!
There is a Russian captcha solver bot called xevil that costs under $100 (I think, last time I looked) that has been able to solve nearly all captchas for years. You just have to supply it with relatively expensive proxy IP addresses because Google rate limits solve attempts.
So the title of this article has been true for a long long time. Capatchas are absolutely useless except against poor or uninformed script kiddies.
That’s suspicious - I can’t pass 100%. here’s a new captcha for you: make the user do 100 in a row
- 100% is ai
- <50% is dumb “ai”
- in between is a person











